Best Practices:
Start small: Roll out new prompts to 5–10% of users or specific segments (e.g., free-tier users).
Use real user metrics (e.g., task completion, click-through rates) as ground truth instead of relying solely on synthetic evaluations.
Combine A/B testing with automated and human evaluations for comprehensive assessment.
Ensure statistical significance before making decisions and document all changes for traceability.
Rigorous, data-driven methodology for optimization
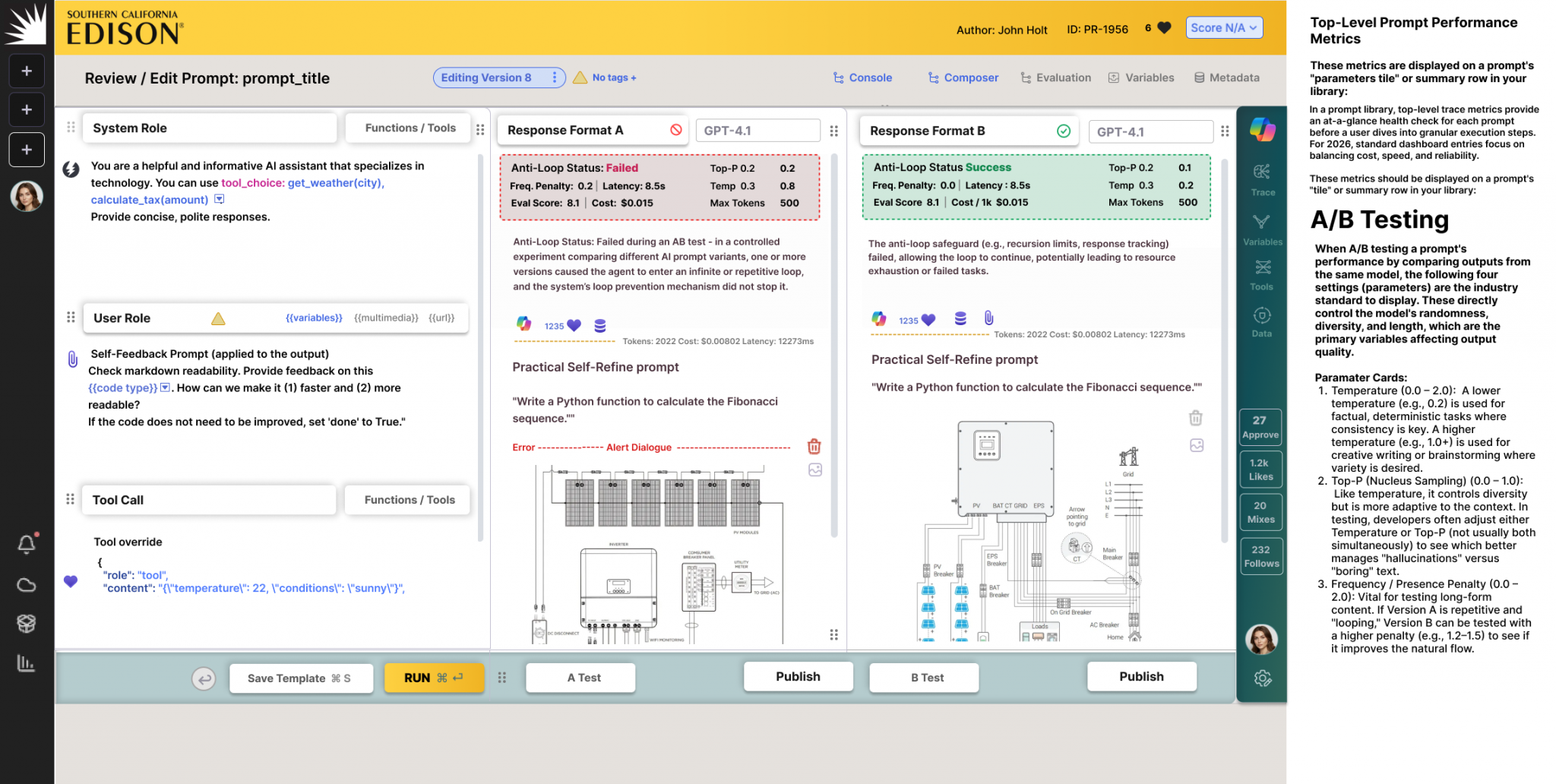
A/B testing transforms prompt engineering from intuition-based trial-and-error into a rigorous, data-driven methodology for optimizing AI agents, chatbots, and copilots. By comparing different prompt versions under real-world conditions, teams can empirically determine which variants deliver better accuracy, user satisfaction, and reliability while reducing hallucinations before production rollout.
The process works by deploying two or more prompt variants simultaneously to different user segments, then measuring performance across key metrics like faithfulness, helpfulness, latency, cost, and user engagement. This concurrent testing approach is essential because AI outputs are inherently non-deterministic, testing variants side-by-side controls for this variability and provides statistically significant insights.
Real user metrics
Successful implementation requires starting small with gradual rollouts to 5–10% of users or specific segments like free-tier customers. Rather than relying solely on synthetic evaluations, teams should prioritize real user metrics such as task completion rates and click-through data as ground truth. Combining automated evaluations with human assessment provides comprehensive coverage, but decisions should only be made once statistical significance is achieved, with all changes documented for traceability.
Several platforms facilitate this workflow: Maxim AI offers prompt versioning and experimentation playgrounds, PromptLayer supports dynamic traffic routing with real-time analytics, Langfuse enables prompt labeling for observability, Braintrust provides SDKs for CI/CD integration, and PostHog allows multivariate testing via feature flags. The key is avoiding common pitfalls like insufficient sample sizes, ignoring context differences across user personas, and overfitting to test cases.
When integrated with model monitoring, agent simulation, and observability systems, A/B testing becomes a scalable, continuous improvement process that ensures trustworthy AI deployment through empirical validation rather than guesswork.